In the aftermath of high profile – and highly impactful – power system failures in recent months, most notably affecting Heathrow airport and the entire Iberian peninsula, UKERC Co-Director Keith Bell reflects on those events and what lessons they hold for ensuring that electricity supplies remain sufficiently resilient as we transition to a low carbon power system.
In this second part of a two-part extended blog, Keith summarises what happened at North Hyde to cause Heathrow airport to shut down. He also discusses some of the principles that guide design and operation of power systems and how we can ensure continued resilience of electricity supply. Read Part 1 here.
All sorts of unplanned things happen on power systems – changes to demand, equipment failures or short-circuit faults caused by the weather (in particular lightning or high winds affecting equipment directly or causing flying debris). In storms such as Arwen in November 2021 or Floris in August 2025, not only are there interruptions to electricity users’ supply but there is damage to overhead lines and blocking of roads makes it difficult for repairs to be carried out. It then becomes essential that good, clear information is given to users so that, if possible, they can make alternative arrangements for heating and hot food, and make sure that vulnerable family members or neighbours are looked after. If it looks like it will take a while, local resilience plans involving local authorities can be put into action to provide refuges and the network company will visit households on the priority services register and, if necessary, provide temporary supplies of power via small generators or batteries.
The network is designed so that there are spare connections to large groups of demand such that if one goes out of service, there is enough capacity elsewhere. However, some reconfiguration of section of network might be necessary to make use of it. This was the case after the fire at National Grid Electricity Transmission’s North Hyde 275 kV substation in March 2025 that led to many hours of disruption at Heathrow airport. Three substations connected the local distribution network to the airport. Each one of them had enough capacity to support all of Heathrow’s demand. However, Heathrow’s own, on-site network was operated in a split configuration; the loss of the connection from North Hyde to one of Heathrow’s substations caused interruptions to everything supplied from that substation. That led Heathrow’s managers to decide to cease flight operations at the airport. What was surprising to a lot of distribution network engineers was that Heathrow’s network reconfiguration plan to re-establish supplies via one of the other substations would take as long as 10-12 hours to work through.

The loss of electricity supply to one of Heathrow airport’s three substations led to the airport being closed. Image: Shutterstock
At North Hyde, there were three ‘supergrid transformers’ (SGTs); just one of them would’ve been enough to support demand for power from the site. A fire on SGT3 caused it to be switched out of service. The fire also caused damage to a ‘marshalling kiosk’ containing monitoring and control equipment for a second transformer; that caused the second transformer to be switched out. The configuration of cables at the site then meant that the third transformer was also switched out.
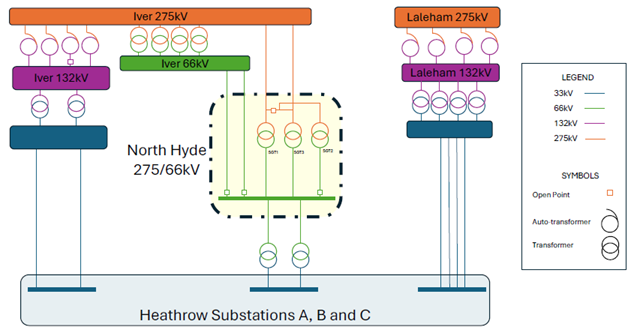
Figure 1: Illustrative standard network configuration and supply to Heathrow Airport. Figure: National Energy System Operator, North Hyde Review Final Report, 30 June 2025.
The incident investigation highlighted some less-than-ideal aspects of the layout of the North Hyde substation, which was built in 1968 to standards that don’t apply today. However, it also underlined the importance of maintenance of old assets. The report by the National Energy System Operator (NESO) noted that the part of SGT3 that most likely caught fire first had shown evidence of such poor condition in 2018 that, according to its owner’s own procedures at the time, it should have been replaced. That had not been done.

Planes were grounded at Heathrow as a result of the fire
The fault at North Hyde was highly unusual in that it broke all connections to and from the site within a very short space of time. The impact for sites supplied from there was severe. This was less for regular distribution network users, the vast majority of whom had their supplies restored within 9 hours or less of the fire, than for Heathrow where it took 11 hours for supplies to be restored to all terminals. However, the impact was localised to only that area and the sections of the distribution network connected directly to North Hyde. Such localisation was not the case in the event on the Iberian peninsula in April.
Interconnected power systems have always been highly complex and dynamic. Major regional or national shutdowns of electricity supply have happened ever since we had power systems at such scale. Throughout my career (over 30 years), system-wide or regional collapses have happened somewhere in the world on average at least once a year. As I noted in part 1, these have affected systems with a wide range of energy sources: fossil fuels, nuclear power, hydropower and renewables. Given the physics of power systems and the disturbances they’re subjected to – Britain’s electricity transmission network typically experiences around 600-700 unplanned outages every year plus numerous losses of generation or interconnectors – it’s perhaps surprising that, usually, only a few of these lead to interruptions energy users’ supplies. This is thanks to ‘secure’ operation. That is, the system operator configures things on the transmission system such that, even if there is sudden outage of a large ‘infeed’ of power, an overhead line, underground cable or transformer, there will be no adverse consequences: voltages and system frequency will stay within acceptable limits, nothing will be overloaded and the system will remain stable. This nips problems in the bud; if that didn’t happen, there is the risk that an overload, an under- or over-frequency, or under- or over-voltage could lead to something else tripping, which causes another problem, setting in motion a cascade of outages.
That’s what happened in Spain and Portugal in April this year.
A problem with power systems throughout the history of power systems is that when they go wrong, they can go very wrong, very quickly. From the disconnection of the first power plant due to the voltage at its point of connection being high enough to trigger a protection device to collapse of the entire Iberian peninsula took less than 30 seconds. One problem that every power system operator should always have been paying attention to, and needs to continue to manage, is the potential for lots of individual items of equipment, each having their own safety settings, to see similar network conditions at about the same time and disconnect within a very short space of time. This can cause large, almost simultaneous losses of generation and – critically for the Spain and Portugal event – the associated voltage control capability.
However, there is a chicken-and-egg dimension to these protection settings and what system conditions might be experienced: they are set according to what writers of documents like the Grid Code think equipment connected to the system can cope with; and designers of equipment and associated protection choose settings according to what the Grid Code says. There can be a degree of arbitrariness and some margin for error. However, as experienced in the German “50.2 Hz problem” in 2012 and in Britain’s “Loss of Mains Change Programme” that finished in 2022, changing the protection settings of thousands of devices can be time-consuming and expensive – around €175 million according to one study for the former, and over £100 million for the latter.
The main conclusion from all of this is that good engineering ensures that even a large, complex, dynamic system can work well but, as I argued in part 1 of this blog, we do need to get the engineering right.
We’re accustomed to our supply of electricity being very reliable. We need to pay close attention to electricity supply resilience not just because we’re heavily dependent on electricity (including for gas-fired central heating) but also because we’ve been making quite big changes to how we generate power: not just where we get the energy from, but also how we connect sources to the network. The main difference lies in the use of electronic switches capable carrying high currents – ‘power electronics’ – within ‘inverters’ that connect sources that use direct current or rotate at varying speeds to the main AC grid. These switches are controlled very precisely in order to synthesise a voltage waveform that integrates well with what’s already on the network, or helps to form a voltage.
There has been quite a lot of talk about ‘inverter-based resources’, such as wind, solar or interconnectors using high voltage direct current (HVDC), lacking the ‘inertia’ that – have. ‘Inertia’ refers to the kinetic energy stored in the rotating mass of each machine that is released or absorbed as conditions on the system change (provided the machines’ physical rotation remains synchronised with the alternation of voltages on the network). This store of energy helps to smooth out variations of power on the network. However, while very useful, it’s not true that it’s utterly essential to stable operation of system: any store of energy will do, provided you can access it quickly enough, either to discharge it or charge it, and have enough of it.
On Britain’s power system, we will still have quite a lot of inertia for some years to come but, if we’re to make full use of wind and solar power when it’s windy and sunny, we need to learn how to stabilise the system without it. The good news is that we’ve been doing exactly that, making use of batteries to provide rapid ‘frequency containment reserve’ – batteries can be charged and discharged quickly and they are interfaced with power electronics for which the control software can be written appropriately.
Incidentally, the cause of the system collapse in Spain and Portugal had nothing to do with inertia in spite of what some people have claimed. Also, although some engineers argue that one of the reasons for using nuclear power to reduce greenhouse gas emissions and our dependency on fossil fuels is that such stations add to system inertia, it’s worth noting that the particular design of the stations that we’re building – at Hinkley Point and Sizewell – increases the need for inertia because of what would happen if a unit there tripped.
As it happens, this isn’t the first time that power system engineers have debated the potential impact of changes to system inertia. We’ve been using synchronous machines for the generation of electricity for over 100 years. However, as single units got ever larger (in pursuit of greater efficiency and lower cost), we needed fewer of them to meet demand at any given time and the amount of stored kinetic energy per unit of electrical power decreased. I can remember this being discussed as a problem in the 1980s. This was not so much from the perspective of management of system frequency but in respect of machines’ ability to remain synchronised with each other with lighter generators, or groups of generators, experiencing bigger accelerations or decelerations in response to system disturbances than heavier ones. This could result in them potentially swinging so far away – and perhaps accelerating uncontrollably – that they needed to be taken offline.
This also isn’t the first time that we’ve worried about power electronics. We made use of very early versions to control the voltage on the rotating part of synchronous machines. Just as with power electronic inverters today, they offered greater flexibility and fast responses to disturbances. However, too big or too fast a response was also implicated in some oscillations that were seen on the system. One particular pattern was observed in the late 1970s and early 1980s on power flows from Scotland to England. It took a number of years of careful study – constraining power flows in the meantime – to come up with a solution (which was installation of ‘power system stabilisers’ on the control systems on certain generators in Scotland, backed up by online monitoring – the ‘wobble meter’ – to give confidence that nothing had been overlooked).
Cases of not getting voltage management right – broadly comparable to what happened in Spain and Portugal this year – can also be seen from the 1980s, a decade in which the French system and Swedish system both experienced voltage collapse. These were attributed, in large part, to increased inter-region power flows and dependency on smaller numbers of sites for voltage control. However, there was one difference from what happened this year: in France and Sweden, voltages got too low; in Spain, voltages first got too high and then collapsed to zero.
The point is that the current period of transition is not the first time that technology changes – introduced for very good reasons – have given rise to power system operation challenges. Those challenges were resolved after intensive study. We need to do the same but, in principle, we have one big advantage compared to the past: we have much more advanced computer technology that allows us to simulate what would happen under a great many different conditions and test different potential remedies. We’ve also introduced new technology gradually and have been able to learn as we’ve gone along.
Power systems exist to supply electricity to end users. To interrupt supply to one of them is bad. To interrupt supply to lots of end users is worse; to do so for many hours is terrible. To collapse an entire system is a disaster as, even if no equipment has been damaged, it could take days to restart the system and resupply everyone, as it did in the North-Eastern US in August 2003. To do it in around 12 hours as they did in Portugal in April 2025, or 16 hours as they did in Spain, is pretty good. In Britain, from the beginning of 2027, NESO will be required to have “sufficient capability and arrangements in place to restore 100% of Great Britain’s electricity demand within 5 days … with an interim target of 60% of regional demand to be restored within 24 hours.”
The definition of resilience that I like best says that a resilient power system prevents disturbances from causing interruptions to supply or, if that’s not possible, contains the extent of interruptions and facilitates safe, rapid restoration of supply. That is, resilience concerns the layers of prevention, containment and recovery.
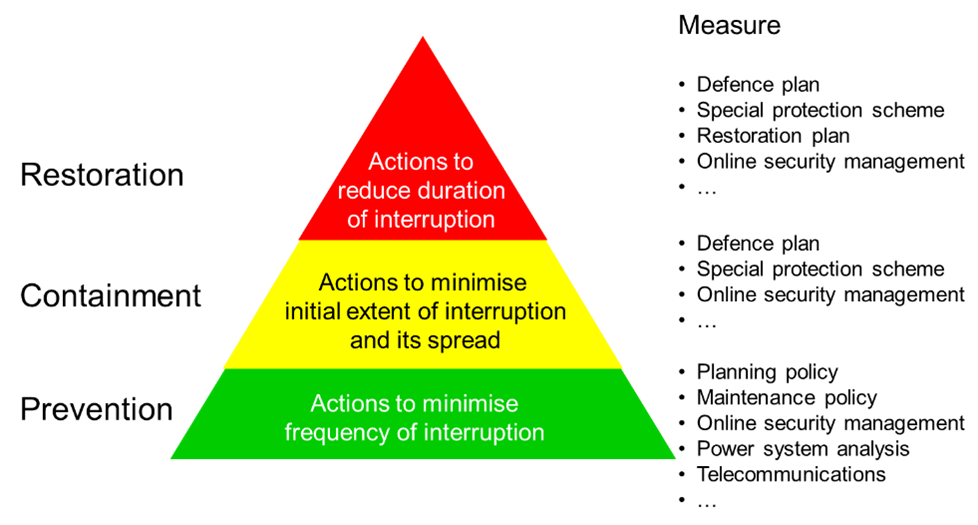
Prevention and containment of the impacts of system disturbances and restoration of power supply after them. CIGRE WG C1.17, “Planning to Manage Power Interruption Events”, Technical Brochure 433, CIGRE, October 2010.
The most common cause of a supply interruption is a fault somewhere on the local distribution network, and the most common cause of faults is bad weather. However, other things can cause outages, including equipment faults, human error, or, on occasion, malign action. In respect of bad weather, we obviously need to be aware of how climate change might affect the frequency and severity of faults.
Disturbances to power systems can unfold over multiple timescales, from the impact on voltages and currents on a scale of milliseconds to seconds, to energy supply shortages that unfold over periods of days to weeks. Control systems can respond within milliseconds – usually to make things better though sometimes they make things worse, and not always because they were designed poorly. Sometimes things are just highly complex. However, to ramp up energy production from a ‘schedulable’ source such as a thermal power station can take hours. What if there aren’t enough power stations? To build a new one can take years. To build a new nuclear power station can take decades.
The key to success is recognising that disturbances do happen and being ready with equipment and plans to contain impacts and facilitate rapid recovery. That was seemingly lacking at Heathrow airport. What happened at North Hyde was quite extreme. However, there are many credible – rare but not impossible – scenarios in which supply to one of Heathrow’s three substations could have been interrupted. Appropriate preparation was needed to ensure that the impact would be minimised.
Although we might first think of physical infrastructure – is there enough of it? Is it sufficiently hardened against extreme weather? Is it well-designed? Is it well-maintained? Is it sufficiently well monitored and controlled? – resilience is not just about engineering. Action in any of those areas might reduce the probability of a disturbance having an adverse impact or contain the size of it. However, resilience also depends on people – the personnel to design, operate and maintain the assets, but also those on whom energy users depend for good information about what’s happened when there’s a fault and when they can expect supplies to be restored. If it’s going to take some hours, how can people keep warm and in touch with each other in the meantime? Who is going look after the most vulnerable, including those who depend on electricity for medical equipment? Good coordination is needed between energy network companies, local authorities, health providers and emergency services in local resilience forums or partnerships.

Storm damage bocking a road
NESO’s report on the North Hyde fire highlighted the importance of electricity supplies to ‘critical national infrastructure’ (CNI). However, according to NESO, “energy network operators are not currently aware whether customers connected to their networks are CNI, and there is currently no cross-sector requirement for CNI operators to ensure specifically the continuity of operations in response to power disruption. Further, CNI operators have no priority within the electricity legal or regulatory framework.”
It surely falls to owners of CNI sites to take at least some responsibility for resilience of energy supplies, to ask questions of their network operator and to put back-up supplies in place. Hospitals, water treatment works, nuclear power stations, telecommunications facilities and so on have standby diesels or batteries, but they need to be confident of how much fuel or charge to store. Moreover, although they depend on electricity supply, in many cases – such as with telecommunications – electricity supply depends on them. There needs to be openness between infrastructure owners about interactions, current practice and whether that practice is sufficient.
One particular challenge is that it’s not easy know what actually is sufficient. We need to start with the right metrics related to resilience. For example, the ‘right’ amount of generation capacity is not solely dependent on peak demand; in a system that’s heavily dependent on renewables, we need to pay attention to residual demand – the difference between demand and what’s available from wind and solar – and the need for a certain volume of storable (and, before too long, low carbon) energy from which to generate electricity to fill in the gaps during extended ‘Dunkelflaute’ periods.
A cost-benefit analysis around high impact, low probability events is very difficult to do, mainly because both the impacts and the probabilities are hard to quantify. It’s also challenging to assess the cost-effectiveness of such a large range of possible actions – in investment, equipment design, logistics, personnel, system operation, and information and communication. However, we shouldn’t let the perfect be the enemy of the good, and we certainly shouldn’t let lack of awareness or lack of priority be any kind of excuse for failure to address ongoing risks associated with random events, and events such as those driven by climate change – intense rainfall, frequent periods of very high winds, and days in summer with very high temperatures – that, at root, are not so random.
Keith Bell holds the Scottish Power Chair in Future Power Systems at the University of Strathclyde and leads the UKERC research theme on delivering energy infrastructure.